Adoption of a modern data platform is a journey. Every step requires different levels of technology, people and process capabilities. A reliable services partner with deep expertise is key for your success at each step of the way. VIP-Global's service model is designed to provide expertise needed at each step of your adoption journey. We defined our offerings to address unique needs at each level.
VIP experts will work with you selecting the right software or tool as well as designing the infrastructure that is both integrated and compatible with your existing infrastructure and operation. VIP has the expertise to prepare your data (ingest, link, match, and cleanse) to enable data relationships and hierarchies.
- Business requirements analysis and conceptual solution elaboration. We start with a detailed overview of your business requirements – both urgent and forward-thinking ones. Based on the requirement list, we deliver a conceptual solution that will meet your short-term and long-term goals.
- Architecture design and technology selection. We suggest an optimal architecture for the solution and help you select the right technology stack among numerous options.
- Implementation. We usually suggest an iterative approach that allows adjusting big data solutions to our customers' business needs.
- Maintenance and support. We not only solve any technical issues, but also proactively support changing business requirements of our customers.
Our services include:
REMOTE DATA ANALYSIS
VIP-GLOBAL works on face-to-face or virtual-remotely style compiling critical data points from your processes and operational databases. Providing remote support is about seeking information from multiple sources and quickly forming conclusions about what's happening, what could happen and what to do to ensure continued positive or improved performance.
BIG DATA ANALYTICS DATA
VIP-GLOBAL's Data Analytics Consultants assisted by specialized analytics systems and software, study big data analytics and point the way to various business benefits, including new revenue opportunities, more effective marketing, better customer service, improved operational efficiency and competitive advantages over rivals.
BIG DATA ECOSYSTEMS
Our data analytics professionals analyze growing volumes of structured transactional data. They also study a variety of forms of data that are often left untapped by conventional business intelligence (BI) and analytics programs. Types of data we work with include:
-
Semi-structured and unstructured data – That includes, internet clickstream data, web server logs, social media content, text from customer emails and survey responses, mobile-phone call-detail records and machine data captured by sensors connected to the internet of things.
-
Data Analytics of data sets and subsequent drawing of conclusions about organizations and how they can make informed business decisions.
-
Advanced Analytics, which involves complex applications with elements such as predictive models, statistical algorithms and what-if analyses powered by high-performance analytics systems.
-
Hadoop distributed processing framework (Apache) open source. A clustered platform built on top of commodity hardware and geared to run big data applications.
-
Hadoop ecosystem for large internet and e-commerce companies, as well for retailers, financial services firms, insurers, healthcare organizations, manufacturers, energy companies and other mainstream enterprises.
BIG DATA TECHNOLOGIES AND TOOLS
-
Data Warehouses that are based on Relational Databases oriented to structured data sets.
-
NoSQL databases as well as Hadoop and its companion tools, including: YARN, MapReduce, Spark engine, HBase, Hive, Kafka, Pig, Hadoop Clusters and Analytical Databases for analysis
-
Organization of Hadoop data lakes that serve as the primary repository for incoming streams of raw data. Data distribution by Hadoop Distributed File System and extract, transform and load (ETL) integration jobs and analytical queries.
-
Data Mining, Predictive Analytics, and Machine Learning, which tap algorithms to analyze large data sets; and Deep Learning, a more advanced offshoot of machine learning.
-
Statistical Analysis and Data Visualization tools. For both ETL and analytics applications, queries can be written in batch-mode MapReduce. Python and Scala; and SQL.
-
Relational databases SQL-on-Hadoop technologies and other open source stream processing engines, such as Flink and Storm.
MAKING YOUR VISION A REALITY
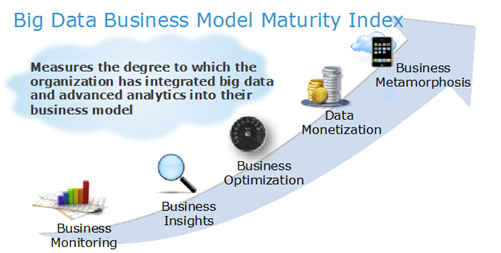
It starts with what you see—not right in front of you, but rather, far ahead. Because what really matters is where you're going. Our Connected Data Platforms can help you create actionable intelligence to transform your business with: Speed. Insight. Flexibility. Affordability.
See how various industries are using connected data platform to achieve amazing things. Will you be the next one to be first in some way? We don't see why not.
- Predictive Analytics - Past is prelude. Historical data provides signals that indicate what may happen in the future. By understanding signals coming from machines and sensors, server logs and other new data sources, organizations can use big data predictive analytics to predict future events and become more proactive.
Hadoop captures, stores and processes the large volumes of data streaming from connected devices and sensors that measure your business. A combination of Hadoop predictive analytics with a variety of data science and iterative machine-learning techniques can make confident real-time recommendations that reduce costs, improve safety, and inform investments.
- Single View: Businesses understand that the single view of customer delivers integrated and unified representation of all data for a complete and contextual understanding of customer behavior. Legacy data systems have been built with a one-to-one relationship between the end application and storage platform. For example, an accounting team manages a payment system with its database, the customer care team stores call logs in a CRM system, and a clinic stores patient data in an EMR platform.
Apache™Hadoop® helps create a single view of customer data and uncovers value that might have been within reach, but scattered across multiple interactions, channels, groups and platforms. Organizations can now leverage single customer view benefits like insights to better target, acquire and retain customers, identify opportunities, overcome challenges and grow revenues.
- Streaming Analytics: Connected Data Platform allows enterprises to seamlessly collect and analyze streaming data from the Internet of Things (IoT) and perform real-time, large-scale and high-speed analytics on this vast volume of data to generate immediate insights. Real-time streaming data and analytics are necessary to achieve the business results enterprises are looking for but building these systems are often painstaking piecemeal integration projects that take an army of individual experts to deliver.
Hortonworks supports streaming analytics and the Internet of Things through Hortonworks DataFlow — an integrated data-source agnostic collection platform powered by Apache NiFi and Apache MiNiFi, along with the powerful streaming analytics capabilities of Apache Kafka and Storm. Together, this enables enterprises to leverage real-time streaming data.
- Enterprise Data Warehouse: Enterprise Data Warehouse (EDW) is an organization's central data repository that is built to support business decisions. EDW contains data related to areas that the company wants to analyze. For a manufacturer, it might be customer, product or bill of material data. EDW is built by extracting data from a number of operational systems. As the data is fed into EDW it is converted, reformatted and summarized to present a single corporate view. Data is added into the data warehouse over time in the form of snapshots and normally an enterprise data warehouse contains data spanning 5 to 10 years. A Hadoop data warehouse architecture enables deeper analytics and advanced reporting from these diverse sets of data.
Case Study: Operator of a public transportation system for the St. Louis metropolitan region
BUSINESS CHALLENGE
To ensure the safety of passengers and the proper use of public funds, MTL has always performed regular maintenance on its bus fleet. But lacking detailed data on how bus components were actually performing, the agency maintained vehicles reactively. It replaced parts after they failed, or simply bought new buses.
SOLUTION
MTL decided to address that conflict by building a proactive bus maintenance program, and in 2002 the city developed the "K Plan" to consolidate its various maintenance divisions. Prior to 2002, each division reported to a different facility.
The specific goals of this K Plan consolidation included:
- Reduced maintenance time for buses
- Accurate predictions for the life spans of different components
- Accurate inventories of required parts to have on hand when needed
- Balanced maintenance workloads so that buses could come in for maintenance at preset, predictable intervals
- Reduced costs for parts and labor
To meet the goals of the K Plan, the MTL developed a new "Smart Bus". The Smart Bus generates machine data as it operates. That data helps the Smart Bus predict and schedule its own maintenance work.
MTL currently leverages the existing electronics on a bus as well as data from all of the main bus subsystems. The data is compressed, transferred into the telemetry backend system, and then stored on Hortonworks Data Platform (HDP®).
RESULTS
With a process to recognize recurring patterns among the day-to-day driving events, MTL is able to better predict when a component on a particular bus will fail, which allows them to proactively service the bus and avoid having to take it out of service for a prolonged period due to unscheduled maintenance events.
Case Study: A public metropolitan research university located on five campuses across the Phoenix, Arizona, metropolitan area, and four regional learning centers throughout Arizona
BUSINESS CHALLENGE
The Complex Adaptive Systems Initiative (CASI) is one of ASU's flagship programs. CASI's research mission was to develop and promote a new type of science that embraces the complexity of natural systems.
ASU's CASI needed to investigate how to better understand and solve the complex problem of cancer, and more specifically, liver cancer. Solutions to such complex problems require storage of massive amounts of data and also powerful data processing tools. Prior platforms for genomics cancer research limited both storage and processing, thus limiting the complexity of questions that investigators could ask and answer.
SOLUTION
The data in a single human genome includes approximately 20,000 genes, which if stored in a traditional platform would represent several hundred gigabytes.
Combining a specialized genomic characterization of one million individually variable DNA locations produces the equivalent of about 20 billion rows of gene-variant combinations. CASI’s Hadoop cluster holds data on thousands of individuals. Now, the CASI team uses Hortonworks Data Platform(HDP®) as a distributed infrastructure to calculate those 20 billion rows that reflect the output of CASI's high-performance computing.
Once they've generated the calculations, the HDP environment lets the team seamlessly query and assemble the resulting information.
RESULTS
When ASU's Research Computing department embarked on building a data-intensive environment, they teamed up to design the system according to the well-defined needs of the university's biomedical researchers. Through HDP, the team avoided complicated machine-to-machine interconnections and wired those interconnections into the distributed framework from the very beginning.
With HDP, ASU is able to have both the availability of data and the technical capability to analyze it. The university ASU researchers rapidly comb the terabytes of cancer data to perform efficient analysis.